Problem
Over the years I have had to adapt to many issues presented before me as a Database Administrator and I have gathered many scripts to deal with them. One that has become quite a topic is XML integration for transactions to the database. In developing this process, my research of resources on the topic throughout the internet, seemed to only discuss primary functions and fundamental application. The following production code is what I used for inserting and updating database tables using XML as the input. These scripts are for processing data for any table to insert or update data. The support functions provided, retrieve the table schema with their data types, functions to deal with XML dates, primary keys of the table and what fields can be updated. The following article breaks down this process from beginning to end.
Solution
First, we need to deal with what data is in the transaction and the format it needs to conform to. For this example, I will be using the pubs database and work with transactions to authors.
Basically, the correctly formatted XML is generated with the table name (authors) as the parent node, rows are delimited by <Row> and the fields are the child nodes, as shown below.
<BookInfo>
<authors>
<Row>
<au_id>172-32-1176</au_id>
<au_lname>White</au_lname>
<au_fname>Johnson</au_fname>
<phone>408 496-7223</phone>
<address>10932 Bigge Rd.</address>
<city>Menlo Park</city>
<state>CA</state>
<zip>94025</zip>
<contract>1</contract>
</Row>
</authors>
</BookInfo>
Note: XML is case-sensitive therefore whatever you have for table names and column names must exactly match the XML.
For those wondering how this is done auto-magically, this select query will generate a sample XML document from the authors table in the pubs database:
SELECT
(
SELECT
(
SELECT au.*
FROM authors au
WHERE au_lname = 'White'
FOR XML PATH('Row'), ELEMENTS, TYPE
) FOR XML PATH ('authors'), TYPE
) "*" FOR XML PATH('BookInfo') Now that we know what we are working with, we can move onto processing the transaction.
I have two processes one for inserting data and another for updating data. I will walk through the Insert and Update processes, so you have a better understanding of how the stored procedures work.
INSERT
In this section, I will walk through the different processes within the Insert stored procedure, which are to extract the NodePath and Table names from the XML, retrieve the schema datatypes, primary keys for that table, prepare the statement and then lastly loop through the XML to perform the request. You can download all of the code for this tip.
The following breaks apart the INSERT stored procedure and I'll explain each step in the process.
This is the first part of the procedure.
-- =============================================
-- Author: WA
-- Create date: 12/24/2009
-- Description: Translate XML to SQL RecordSet for INSERT
-- Dependencies: [dbo].[fnGetTableSchemaInsert], [dbo].[fnSetTableSchemaSelect],
[dbo].[fnGetTableSchemaSelectInto],[dbo].[fnIsDate]
-- =============================================
CREATE PROCEDURE [dbo].[prXMLDataInsert]
(
@XmlData XML
)
AS
BEGIN
SET NOCOUNT ON
SET ARITHABORT ON
SET CONCAT_NULL_YIELDS_NULL ON
SET QUOTED_IDENTIFIER ON
SET ANSI_NULLS ON
SET ANSI_PADDING ON
SET ANSI_WARNINGS ON
SET NUMERIC_ROUNDABORT OFF
DECLARE @hdoc INT
-- Prepare XML document
EXEC sp_xml_preparedocument @hdoc OUTPUT, @xmlData After testing several XML methods, the quickest way I found was to use the sp_xml_preparedocument then insert the results into a temporary dataset in order to quickly query values from the XML to process.
-- Set Raw XML Schema
SELECT *
INTO #xmlDoc
FROM OPENXML( @hdoc, '//*',2) Once we have the dataset, our example XML data would appear as below:
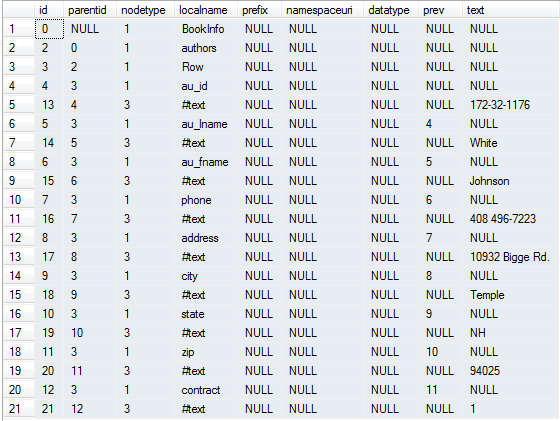
The next step is to get the NodePath and table names from our temp dataset by using the query below:
-- Set Primary Table to use
SELECT DISTINCT IDENTITY(INT,1,1) id, rt.localname + '/' + tbl.localname + '/'
+ col.localname AS NodePath, tbl.localname AS NodeRow
INTO #xml
FROM #xmlDoc rt
INNER JOIN #xmlDoc tbl
ON rt.id = tbl.parentID AND rt.parentID IS NULL
INNER JOIN #xmlDoc col
ON tbl.id = col.parented The results of the query would then appear as follows:

At this point, we are ready to loop through the XML data as illustrated below. A few points of interest, I used a while loop verses a cursor to keep down the resource overhead and keep the speed up, and for those that haven't learned the hard way with sp_executesql since we have to pass in the XML into the statement, we only have nvarchar(4000) to store the statement, which causes chaos when you have tables with many columns.
DECLARE @i INT, @NodePath VARCHAR(255), @NodeRow VARCHAR(50),
@NodeKeys VARCHAR(255), @NodeCol VARCHAR(2000),
@UpdateNodes VARCHAR(2000), @sSql NVARCHAR(4000),
@SetSchemaSelect VARCHAR(4000), @iVars VARCHAR(2000)
-- Set id of first row
SELECT @i = MIN(id) FROM #xml
-- Begin looping through xml recordset
WHILE @i IS NOT NULL
BEGIN
SELECT @NodePath = NodePath, @NodeRow = NodeRow FROM #xml WHERE id = @i What I found in order to build out the statements correctly, we need to get the column schema for the table were inserting into, but not any auto increment keys. Build the SELECT statement for the INTO portion of the statement and our OPENXML WITH fields with the correct datatypes, using the following functions illustrated below.
-- Get Table Schema for XML data columns
SELECT @NodeCol =[dbo].[fnGetTableSchemaInsert](@NodeRow)
SELECT @SetSchemaSelect = [dbo].[fnSetTableSchemaSelect](@NodeRow)
SELECT @ivars = [dbo].[fnGetTableSchemaSelectInto](@NodeRow)
DECLARE @param NVARCHAR(50), @pkID INT, @pkIDOUT INT
SET @param = N'@hdoc INT, @pkIDOUT INT OUTPUT' For our sp_executesql we need to SET the @hdoc and can pass the identity value back if there is one for the table. As we continue, we have set our INSERT variables and now can build our final statement to execute.
-- This updates xml Recordset on primary keys of a given table
SET @sSql = 'INSERT INTO ' + @NodeRow + '(' + @iVars + ') SELECT ' + @SetSchemaSelect +
' FROM OPENXML( @hdoc, ''' + @NodePath + ''',2) WITH (' + @NodeCol + ') as xm SELECT @pkIDOUT = SCOPE_IDENTITY()' A sample of the final statement generated from the above line of code would appear as:
INSERT INTO authors(au_id,au_lname,au_fname,phone,address,city,state,zip,contract) SELECT [au_id], [au_lname], [au_fname], [phone], [address], [city], [state], [zip], [contract] FROM OPENXML( @hdoc, 'BookInfo/authors/Row',2) WITH ([au_id] VARCHAR(11), [au_lname] VARCHAR(40), [au_fname] VARCHAR(20), [phone] CHAR(12), [address] VARCHAR(40), [city] VARCHAR(20), [state] CHAR(2), [zip] CHAR(5), [contract] bit) AS xm SELECT @pkIDOUT = SCOPE_IDENTITY() Note: Here is where we can get in trouble with the nvarchar(4000) limit when the statement is dynamically assembled.
/******* Execute the query and pass in the @hdoc for update *******/
EXEC sp_executesql @sSql, @param, @hdoc, @pkIDOUT=@pkID OUTPUT
/***** Movenext *****/
SELECT @i = MIN(id) FROM #xml WHERE id > @I
END
-- Release @hdoc
EXEC sp_xml_removedocument @hdoc
DROP TABLE #xmlDoc
DROP TABLE #xml
END UPDATE
Well I have explained the XML INSERT, now to we can step through the UPDATE process, which fundamentally goes through the same steps as the INSERT, but the functions for this stored procedure generate update values for the sp_executesql loop.
-- =============================================
-- Author: WA
-- Create date: 12/24/2009
-- Description: Translate XML to SQL RecordSet for UPDATE
-- Dependencies: [dbo].[fnGetTableSchema], [dbo].[fnGetTableUpdate],
-- [dbo].[fnGetPrimaryKeys],[dbo].[fnIsDate], [dbo].[fnGetTableKeys]
-- =============================================
ALTER PROCEDURE [dbo].[prXMLDataUpdate]
(
@XmlData XML
)
AS
BEGIN
SET NOCOUNT ON
SET ARITHABORT ON
SET CONCAT_NULL_YIELDS_NULL ON
SET QUOTED_IDENTIFIER ON
SET ANSI_NULLS ON
SET ANSI_PADDING ON
SET ANSI_WARNINGS ON
SET NUMERIC_ROUNDABORT OFF
DECLARE @hdoc INT
-- Prepare XML document
EXEC sp_xml_preparedocument @hdoc OUTPUT, @xmlData
-- Set Raw XML Schema
SELECT *
INTO #xmlDoc
FROM OPENXML( @hdoc, '//*',2)
-- Set Primary Table to use
SELECT DISTINCT IDENTITY(INT,1,1) id, rt.localname + '/' + tbl.localname + '/'
+ col.localname AS NodePath, tbl.localname AS NodeRow
INTO #xml
FROM #xmlDoc rt
INNER JOIN #xmlDoc tbl
ON rt.id = tbl.parentID AND rt.parentID IS NULL
INNER JOIN #xmlDoc col
ON tbl.id = col.parented
DECLARE @i INT, @NodePath VARCHAR(255), @NodeRow VARCHAR(50), @NodeKeys VARCHAR(255), @NodeCol VARCHAR(4000), @UpdateNodes VARCHAR(4000), @sSql NVARCHAR;-- -
--Set id of first row
SELECT @i = MIN(id) FROM #xml;
-- Begin looping through XML recordset to check for exists
WHILE @i IS NOT NULL
BEGIN
SELECT @NodePath = NodePath, @NodeRow = NodeRow
FROM #xml
WHERE id = @i
-- Get Table Schema for XML data columns
SELECT @NodeCol = [dbo].[fnGetTableSchema](@NodeRow)
SELECT @UpdateNodes =[dbo].[fnGetTableUpdate](@NodeRow)
SELECT @NodeKeys = [dbo].[fnGetPrimaryKeys](@NodeRow) Just as the INSERT our sp_executesql will need to SET the @hdoc parameter and optionally pass the identity value back if there is one for the table.
DECLARE @param NVARCHAR(50)
SET @param = N'@hdoc INT' At this point, we have set our UPDATE variables and can now build our final statement to execute.
SET @sSql = 'UPDATE ' + @NodeRow + ' SET ' + @UpdateNodes + ' FROM
OPENXML( @hdoc, ''' + @NodePath + ''',2) WITH (' +
@NodeCol + ') as xm INNER JOIN ' + @NodeRow + ' ON ' +
@NodeKeys A sample of the final statement generated would appear as:
UPDATE authors SET [au_lname] = xm.au_lname, [au_fname] = xm.au_fname, [phone] = xm.phone, [address] = xm.address, [city] = xm.city, [state] = xm.state, [zip] = xm.zip, [contract] = xm.contract FROM OPENXML( @hdoc, 'BookInfo/authors/Row',2) WITH ([au_id] VARCHAR(11), [au_lname] VARCHAR(40), [au_fname] VARCHAR(20), [phone] CHAR(12), [address] VARCHAR(40), [city] VARCHAR(20), [state] CHAR(2), [zip] CHAR(5), [contract] bit) AS xm INNER JOIN authors ON authors.au_id=xm.au_id Note: Let me pass a few words of wisdom concerning the OPENXML and WITH function. First the XML field values are all for practical purposes varchar, which is why we declare the Datatypes in the WITH section. When we have a datetime value to process, a value of NULL is translated to 1900-01-01 00:00:00.000, which is why I created the fnIsDate() function to turn it back to NULL.
-- Execute the query and pass in the @hdoc for UPDATE
EXEC sp_executesql @sSql, @param, @hdoc
/***** Movenext *****/
SELECT @i = MIN(id) FROM #xml WHERE id > @I
END Finally, need to insure that we release the variables before returning
-- Release @hdoc
EXEC sp_xml_removedocument @hdoc
DROP TABLE #xmlDoc
DROP TABLE #xml
END Putting It Together
Now that we have walked through the code for the Insert and Update these are functions that are required and are all part of the code download.
Functions:
- [dbo].[fnGetTableSchemaInsert]
- [dbo].[fnSetTableSchemaSelect]
- [dbo].[fnGetTableSchemaSelectInto]
- [dbo].[fnIsDate]
- [dbo].[fnGetTableSchema]
- [dbo].[fnGetTableUpdate]
- [dbo].[fnGetPrimaryKeys]
- [dbo].[fnGetTableKeys]
Stored Procedures:
- prXMLDataInsert
- prXMLDataUpdate
Examples
After you have created all of these objects in your database (in our case the pubs database) we can then use them to create new records or update existing records.
In this first example I have modified the fname to be "John" and the lname to be "Doe".
SELECT * FROM authors WHERE au_id = '172-32-1176';
EXEC dbo.prXMLDataUpdate
'<BookInfo>
<authors>
<Row>
<au_id>172-32-1176</au_id>
<au_lname>John</au_lname>
<au_fname>Doe</au_fname>
<phone>408 496-7223</phone>
<address>10932 Bigge Rd.</address>
<city>Menlo Park</city>
<state>CA</state>
<zip>94025</zip>
<contract>1</contract>
</Row>
</authors>
</BookInfo>';
SELECT * FROM authors WHERE au_id = '172-32-1176'; Here are the before and after values in the table.
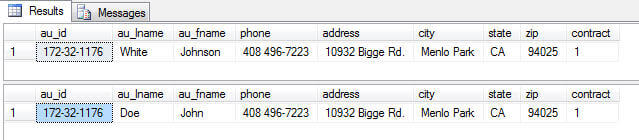
In this example we will create a new author with an ID = '999-99-9999'
SELECT * FROM authors WHERE au_id = '999-99-9999';
EXEC dbo.prXMLDataInsert
'<BookInfo>
<authors>
<Row>
<au_id>999-99-9999</au_id>
<au_lname>Doe</au_lname>
<au_fname>John</au_fname>
<phone>408 496-7223</phone>
<address>10932 Bigge Rd.</address>
<city>Menlo Park</city>
<state>CA</state>
<zip>94025</zip>
<contract>1</contract>
</Row>
</authors>
</BookInfo>';
SELECT * FROM authors WHERE au_id = '999-99-9999'; Here are the before and after values in the table.
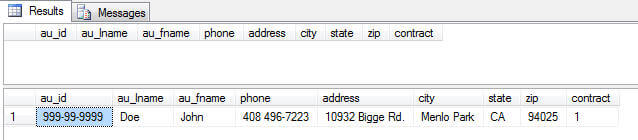
Next Steps
- Remember XML is case-sensitive so any table name, column name, procedure or parameter must be exactly the same as the XML your trying to submit in the transaction.
- sp_executeSQL is a good function, but has a nvarchar(4000) character limit for the statement, so building INSERT or UPDATE queries dynamically can truncate with tables that have many columns and fail to execute.
- You can add a return dataset or pass the scope-identity on INSERT
- This same process can be applied to executing store procedures instead of direct INSERT/UPDATES of tables. Same rules apply with case-sensitive procedure names and parameters.
- Finally, beware the XML datetime datatype, you will bang your head off the keyboard trying trouble shoot, like I did.
- Download the code. If formatting is hard to read, right click and do a Save As to save the file locally.
No comments:
Post a Comment